Bu makalede teknik detaylara girmeden sadece yüzeysel olarak YOLO nedir ve nasıl kullanılır bunlardan bahsedeceğim.
YOLO Nedir?
YOLO (You Only Look Once), gerçek zamanlı olarak nesne algılama algoritmasıdır. Bu algoritma Evrişimli Sinir Ağı (CNN) yöntemini kullanır. Bu yöntem ile görüntüyü bölgelere ayırır ve her bölge için olasılıkları tahmin eder, bu sayede doğruluk oranı oldukça yüksektir.
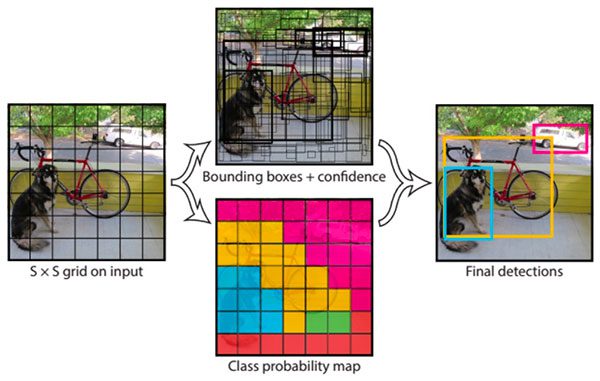
YOLO algoritması, adının hakkını vererek sinir ağından-görüntüye sadece bir kez bakar. Bu işlem, gerçek zamanlı çalışabilmesinin yanı sıra yüksek doğruluk oranı sağladığı için YOLO algoritmasını popüler kılıyor.
YOLO Modelleri
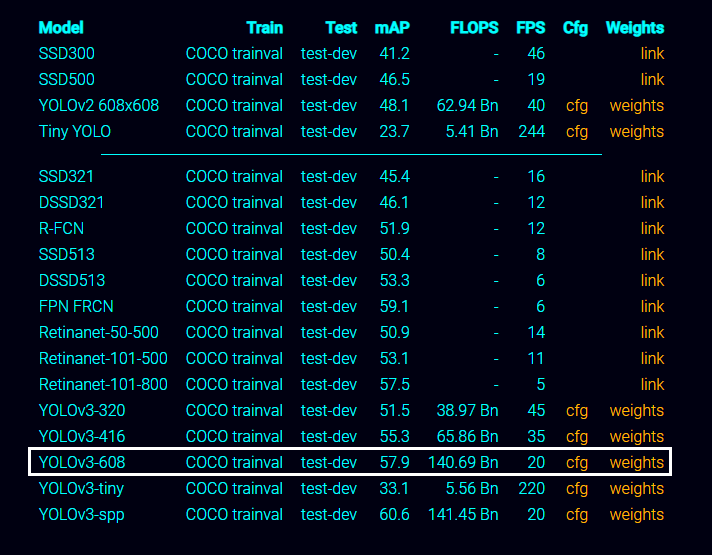
Birkaç farklı seçenek görüyorsunuz. Bu modeller, farklı boyutlardaki görüntüler için eğitilmiştir.
320 x 320 (yüksek hız, daha az doğruluk),
416 x 416 (orta hız, orta doğruluk),
608 x 608 (daha düşük hız, yüksek doğruluk)
İstediğiniz modeli kullanabilirsiniz. Ancak ben YOLOv3–608 modelini kullanacağım.
İndirmemiz gereken 3 dosya var. Model, konfigürasyon ve nesnelerin isim dosyası.
Modeli indirmek için tıklayın yolov3.weights
Konfigürasyon dosyası için tıklayın yolov3.cfg
Nesne isim dosyası için tıklayın coco.names
YOLO Modelini OpenCV ile Algılamak
Gelelim kod kısmına. İndirdiğimiz modelin (yolov3 ağırlık dosyası) ve konfigürasyon (cfg) dosya yolunu net değişkenine yazıyoruz.
Coco.names dosyası, eğitilen nesnelerin adlarını içerir. Bunları classes(sınıflar) adı verilen bir listede saklıyoruz.
Diğerlerini kod arasında yorum satırı olarak açıkladım.
from cv2 import cv2
import numpy as np
import glob
import random
# Model ve cfg dosya yollarını yazın
net = cv2.dnn.readNet("yolov3.weights", "yolov3.cfg")
# Nesne isimlerini 'coco.names' dosyasından çekme
classes = []
with open("coco.names", "r") as f:
classes = [line.strip().capitalize().strip() for line in f.readlines()]
# Resim yolu
images_path = glob.glob(r"resimler\*.jpg")
layer_names = net.getLayerNames()
output_layers = [layer_names[i - 1] for i in net.getUnconnectedOutLayers()]
colors = np.random.uniform(255, 0, size=(len(classes), 3))
random.shuffle(images_path)
for img_path in images_path:
img = cv2.imread(img_path)
# Görsel boyutu büyük ise yorum satırını kaldırıp yeniden boyutlandırabilirsiniz
# img = cv2.resize(img, None, fx=0.4, fy=0.4)
height, width, channels = img.shape
# Detecting objects
blob = cv2.dnn.blobFromImage(img, 0.00392, (416, 416), (0, 0, 0), True, crop=False)
net.setInput(blob)
outs = net.forward(output_layers)
class_ids = []
confidences = []
boxes = []
for out in outs:
for detection in out:
scores = detection[5:]
class_id = np.argmax(scores)
confidence = scores[class_id]
# Doğruluk oranı kaçtan itibaren algılamasını istiyosanız kendiniz belirleyebilirsiniz
if confidence > 0.3:
center_x = int(detection[0] * width)
center_y = int(detection[1] * height)
w = int(detection[2] * width)
h = int(detection[3] * height)
# Rectangle coordinates
x = int(center_x - w / 2)
y = int(center_y - h / 2)
boxes.append([x, y, w, h])
confidences.append(float(confidence))
class_ids.append(class_id)
indexes = cv2.dnn.NMSBoxes(boxes, confidences, 0.5, 0.4)
for i in range(len(boxes)):
if i in indexes:
x, y, w, h = boxes[i]
# print(f"{round(confidences[i],2)}")
dogruluk = (f"%{round(confidences[i],2)}")
label = (f"{classes[class_ids[i]]} {dogruluk}")
color = [int(c) for c in colors[class_ids[i]]]
cv2.rectangle(img, (x, y), (x + w, y + h), color, 2)
# Text arka planı için text boyutunu alıyoruz
(w, h), _ = cv2.getTextSize(label, cv2.FONT_HERSHEY_SIMPLEX, 0.5, 1)
# Text arka planını çiziyoruz
textBg = cv2.rectangle(img, (x, y - 15), (x + w, y), color, -1)
# Etiketi yazdırıyoruz
cv2.putText(textBg, label, (x, y-3), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255,255,255), 1)
cv2.imshow("Image", img)
# Çıktıyı kayıt et
# cv2.imwrite("resim.png", img)
key = cv2.waitKey(0)
cv2.destroyAllWindows()

Model eğitecek sisteminiz yoksa, colab kullanamıyorsanız, bu tip hazır modeller üzerinden projeler geliştirebilirsiniz.
Gerçek zamanlı nesne algılama kodları için Github’a Göz Atın.
Diğer projelere ulaşmak için tıklayın.