

Merhaba,
Python’da BeautifulSoup modülü kullanarak, imdb’nin top 250 listesini Web Scraping işlemi ile nasıl çekebileceğimizi anlatacağım.
İlk olarak gerekli modülleri aşağıdaki gibi kuralım;
pip install requests
pip install beautifulsoup4Daha sonra modülleri import edelim;
import requests
from bs4 import BeautifulSoup
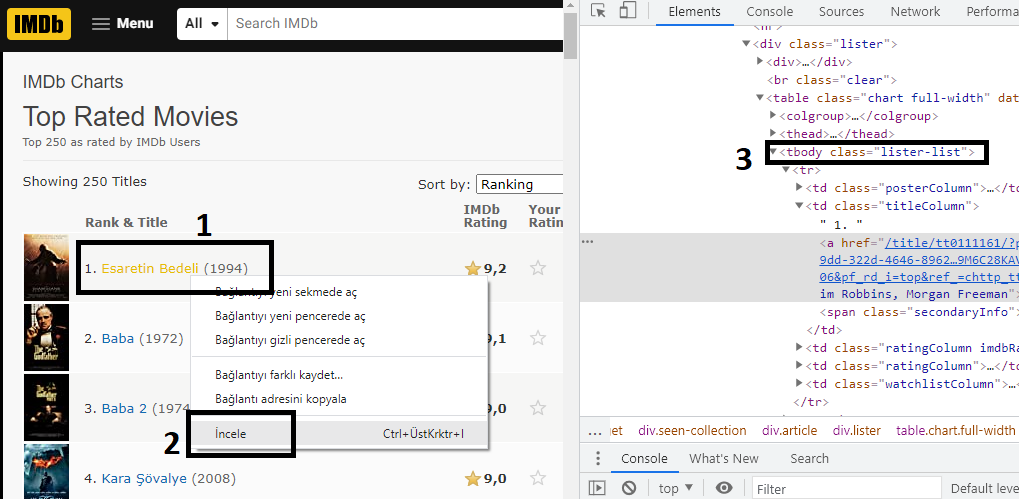
Web Scraping işlemi yaparken verilerini çekeceğimiz sitenin kaynak kodlarını incelememiz gerekiyor. Bunun sebebi, kaynak koddaki etiketler ile yazacağımız koddaki etiketlerin aynı olması lazım.
requests modülü ile URL’ye istek gönderip kaynak kodlarını çekiyoruz, BeautifulSoup ile kodları parse işlemini gerçekleştiriyoruz.
url = "https://www.imdb.com/chart/top/?ref_=nv_mv_250"
r = requests.get(url).content
soup = BeautifulSoup(r, "html.parser")
Daha sonra incelediğimiz kaynak kodlardaki çekeceğimiz verinin etiketini find() metodu ile istediğimiz verileri çekebiliriz.
list = soup.find("tbody", {"class":"lister-list"}).find_all("tr",limit=250)
s = 1
for i in list:
title = i.find("td",{"class":"titleColumn"}).find("a").text
yil = i.find("span",{"class":"secondaryInfo"}).text.strip("()")
rating = i.find("td",{"class":"ratingColumn"}).find("strong").text
print(f"{s}. {title.ljust(50)} {yil} Rating: {rating}")
s += 1
Çıktı;

BeautifulSoup modülü hakkında daha fazlası için tıklayın
Tüm kodlara ulaşmak için Github’a Göz Atın.
Diğer projelere ulaşmak için tıklayın.






